ABOUT ME
Zheqi He - 何哲琪
Master Student
Institute of Computer Science and Technology
Peking University
BACKGROUND
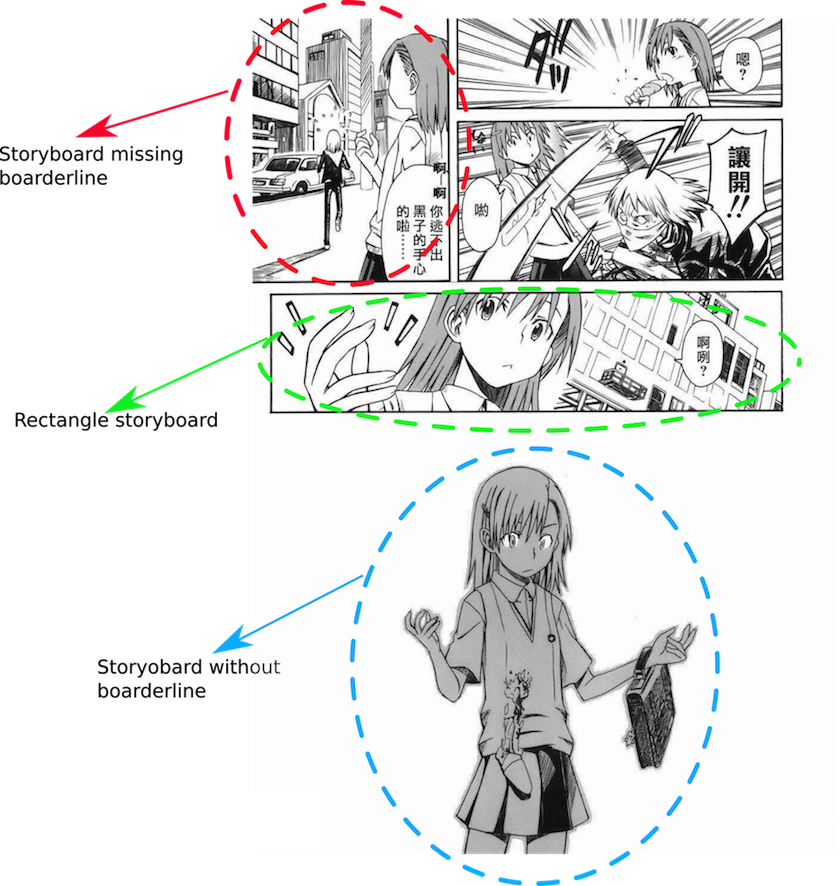
Comics, defined as “juxtaposed pictorial and other images in deliberat esequence, intended to convey information and/or to produce anaesthetic response in theviewer”, have gained increasing popularity since it sappearance in the 19th century. In this era, Comic is a kind of entertainment publication popular among people of different ages around the world. The storyboard is the basic semantic unit of a comic, as shown in Fig.1, hence, decomposing the comic image into several storyboards is the fundamental step to understand content of comic.
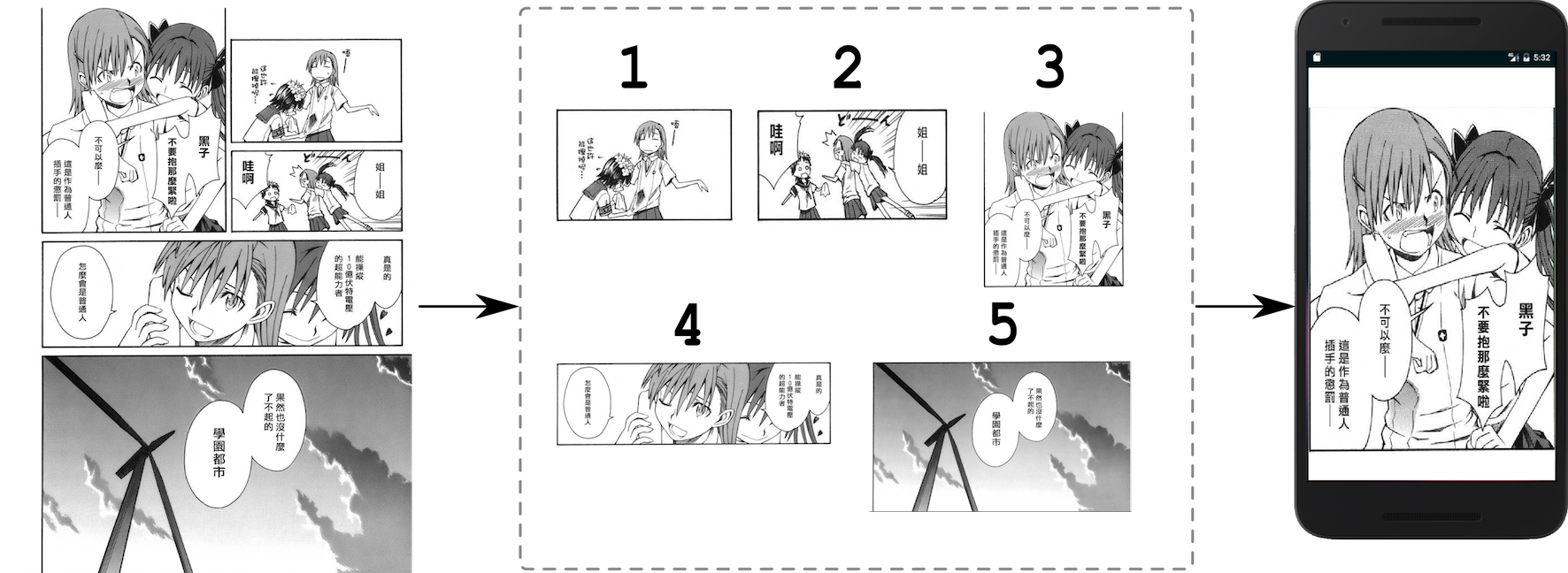
In addition, decomposing the comic image into several storyboards is the key technique to produce digital comic documents suitable for reading on mobile devices with small screen. Fig.2 gives an example.
MOTIVATION
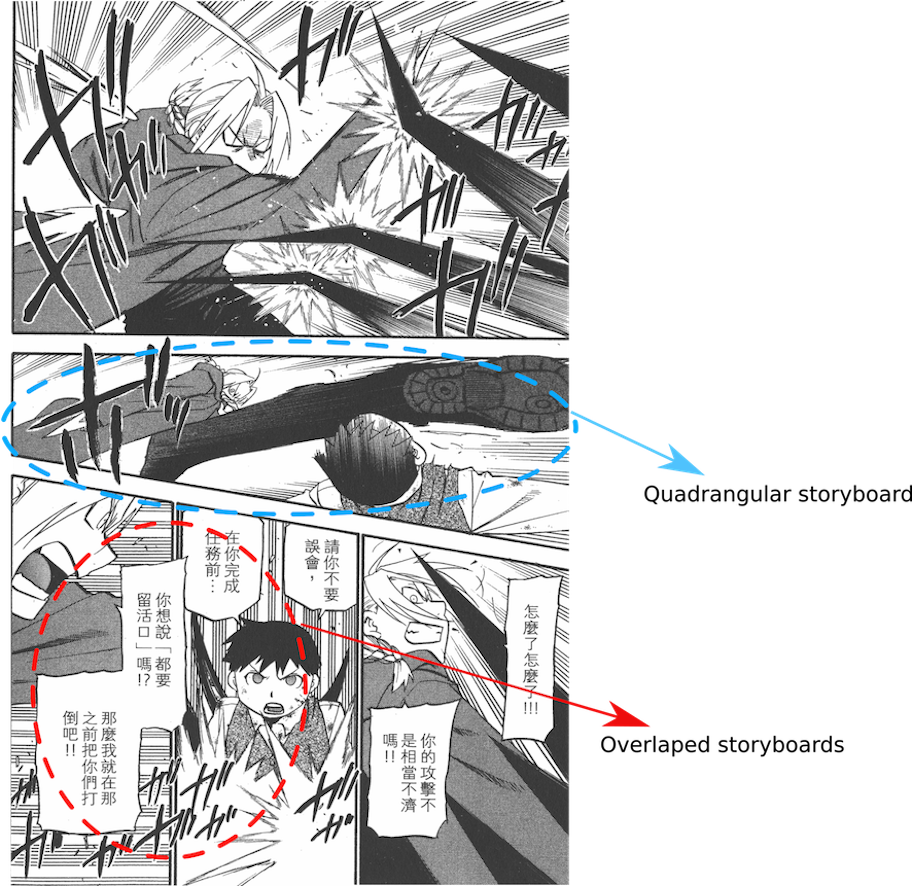
Most of previous storyboard extraction methods [Wang, Zhou, and Tang 2015; Li et al. 2015] use only hand crafted low-level visual patterns, such as edge segments, line segments or connected component. These methods analyze the relationship between low-level visual patterns and combine them into storyboard. These methods work effectively under certain assumptions, but they may fail to handle the comic image with complex layout. For example, when storyboards missing borderlines, these methods cannot handle them well; or when there are complex overlaps between storyboards, these methods are tend to fail. The most important reason is low-level visual patterns can not represent image content well.
Recently, deep learning methods[Girshick 2015; Liu et al. 2015] have been applied to object detection and gain the state-of-the-art performances. The effective feature learning capability of deep neural network make great contribution to high-level vision tasks. However, these methods can only obtain rectangle bounding box of objects, which are not precise enough for many application tasks. For example, for the tasks of comic storyboard detection or traffic sign detection. It is better to use parameterized shape like triangle, quadrangle or ellipse to express detected results.
METHOD
In this paper, we propose a novel architecture based on deep convolutional neural network namely SReN to detect storyboards within comic images. Fig.3 illustrate the architecture of SReN, which consists of two main steps: generate storyboard proposals and train shape regression network.
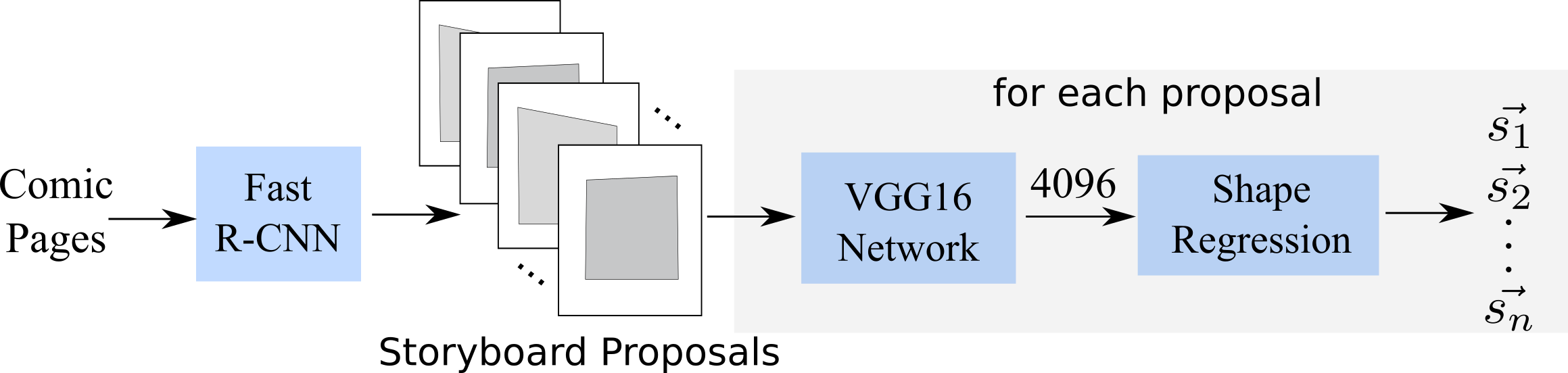
Generating storyboard proposals
We use comic images to train a Fast R-CNN model to detect storyboard rectangle bounding boxes r. The reason we use Fast R-CNN rather than Faster R-CNN [Ren et al. 2015], which performs better than Fast R-CNN in many challenges like Pascal VOC or COCO, is that Faster R-CNN has bad performance when we require high localization accuracy. Since Fast R-CNN can only generate rectangle bounding boxes, we use corresponding exterior rectangles as ground truth for storyboards. But these bounding boxes often miss some parts of a storyboard, in order to obtain the complete storyboard, we enlarge r by a factor of 1.1 to generate storyboard proposal p as the input of our SReN. Another problem is that storyboards are often various in sizes, to reduce the interference of this, we normalize the vertexes of storyboard proposals into [-1, 1], that is
where (x', y') is the vertex of the regression target, (x, y) is the vertex of the original storyboard, (c_x, c_y) is the center of the storyboard, w and h is the width and the height of the storyboard proposal.
Training shape regression network
Firstly, we sorted the regression target
,
where
, of the storyboard by it
is polar angle.
Then we use $p$ and their regression targets as the input of VGG16 network [Simonyan and Zisserman
2015]
to get feature f with 4096 dimensions. Finally we add a fully connected layer to regress the vertexes
of the storyboard
,
where
, as storyboards are quadrangle,
we set n = 4. Like Fast R-CNN, we use the loss function:
where
Implementation details
For the implementation code of our paper, we make use of the Caffe framework[Jia et al. 2014] and tran SReN with a Titan X.
When training Fast R-CNN, We treat all region proposals with > 0.8 IoU overlap with a ground-truth box as positives, the rest as negative. We start SGD at a learning rate of 0.001, in each SGD iteration, the size of mini-batch is 128, which consist of 32 positive and 96 negative. When training Regression Network, we start SGD at a learning rate of 0.001 and reduce ten times after every 20000 iterations, we set the batch size equal to 64.
EXPERIMENT
Dataset
We construct a dataset with 29845 labeled comic pages (contain 169421 storyboards) from 103 different comic books, which come from different Japanese and Hong Kong comics. We randomly select 15087 of the labeled comic pages to train SReN, we use another 7375 comic pages to validate the training result and conduct experiments on the remaining 7382 comic pages. Therefore, the proportion of train, evaluate and test dateste is about 5 : 2.5 : 2.5.
Evaluation criteria
We evaluate results on two levels: storyboard level and page level. On the storyboard level, we use precision, recall and F1 score as evaluation metrics. On the page level, we use page correction rate(PCR) as evaluation criterion, i.e., the ratio of comic pages in which all storyboards are correctly detected. To be more specific, each detected storyboard is represented by a quadrangle, if the intersection-over-union(IoU) between the detected storyboard and the corresponding ground truth is more than 90\%, we regard it as a correct detected storyboard for the comic page. IoU for each ground truth and detected storyboards is defined as following,
where
is a set of detected storyboards,
is the manually label for each storyboard within the page. The intersection and the union
operation are calculated in terms of area.
Results
We compare our method with Fast R-CNN without shape regression and two low-level visual patterns based methods: TCRF[Li et al. 2015] and ESA[Wang, Zhou, and Tang 2015]. Experimental results are listed in Table 1, which indicate that:
- The deep learning based methods can achieve much better results than hand crafted low-level visual patterns based methods.
- Fast R-CNN with SReN is better than vanilla Fast R-CNN by the effective shape regression.
| Method | Precision | Recall | F1 score | PCR |
|---|---|---|---|---|
| ESA | 0.835 | 0.700 | 0.762 | 0.418 |
| TCRF | 0.699 | 0.64 | 0.668 | 0.399 |
| Fast R-CNN | 0.807 | 0.799 | 0.803 | 0.518 |
| SReN | 0.888 | 0.879 | 0.883 | 0.640 |
Samples of extraction results of comic pages are as following:



DISCUSSION
In this paper, we propose a novel deep architecture to detect storyboards within comic images, namely SReN. The main contribution is to use a shape regression network to regress the vertexes of quadrilateral storyboards in comic pages. Experimental results demonstrate that SReN performs better than two state-of-the-art storyboards extraction methods and object detection methods. In the future, we will test our idea on other shapes, like ellipse and triangle, which can be used in traffic sign detection and other applications. We also want to investigate how to design an end-to-end model to automatically detect and regression the target shape.
REFERENCE
- wang2015comic
- Wang Y, Zhou Y, Tang Z. Comic frame extraction via line segments combination[C]//Document Analysis and Recognition (ICDAR), 2015 13th International Conference on. IEEE, 2015: 856-860.
- li2015tree
- Li L, Wang Y, Suen C Y, et al. A tree conditional random field model for panel detection in comic images[J]. Pattern Recognition, 2015, 48(7): 2129-2140.
- liu2015ssd
- Liu W, Anguelov D, Erhan D, et al. SSD: Single Shot MultiBox Detector[J]. arXiv preprint arXiv:1512.02325, 2015.
- girshick2015fast
- Girshick R. Fast r-cnn[C]//Proceedings of the IEEE International Conference on Computer Vision. 2015: 1440-1448.
- simonyan2015very
- Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
- jia2014caffe
- Jia Y, Shelhamer E, Donahue J, et al. Caffe: Convolutional architecture for fast feature embedding[C] //Proceedings of the 22nd ACM international conference on Multimedia. ACM, 2014: 675-678.
- ren2015faster
- Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]//Advances in neural information processing systems. 2015: 91-99.